What is Machine Learning (ML)? Learn Everything You Need to Know
-Learn-Everything-You-Need-to-Know.png)
Machine Learning can be defined as a subset of Artificial Intelligence (AI) that focuses on the development of algorithms and models that allow computers to learn and improve from experience. Unlike traditional programming paradigms where explicit instructions are provided to perform specific tasks, machine learning systems leverage data to autonomously identify patterns, trends, and correlations, subsequently using this knowledge to make informed decisions or predictions.
Data Collection: Gathering relevant and diverse datasets that contain the information necessary for training and evaluation.
Preprocessing: Cleaning, transforming, and preparing the data to ensure its quality and compatibility with the learning algorithms.
Model Training: Utilizing various machine learning algorithms to train models on the prepared data, allowing them to learn patterns and relationships.
Evaluation: Assessing the performance of the trained models using metrics and techniques tailored to the specific problem domain.
Deployment: Integrating the trained models into real-world applications where they can make predictions or decisions based on new, unseen data.
Machine learning techniques can be broadly categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning.
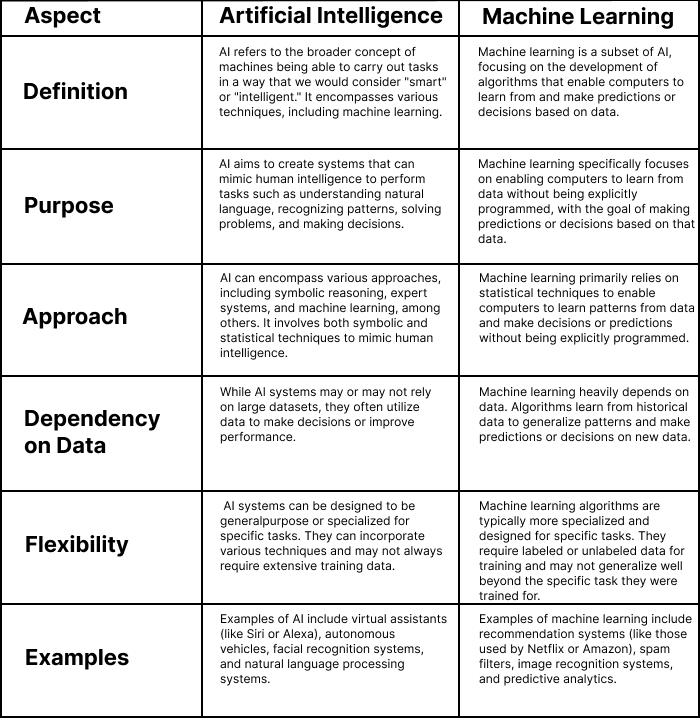
1. Definition:
AI (Artificial Intelligence): AI refers to the broader concept of machines being able to carry out tasks in a way that we would consider "smart" or "intelligent." It encompasses various techniques, including machine learning.
Machine Learning: Machine learning is a subset of AI, focusing on the development of algorithms that enable computers to learn from and make predictions or decisions based on data.
2. Purpose:
AI: AI aims to create systems that can mimic human intelligence to perform tasks such as understanding natural language, recognizing patterns, solving problems, and making decisions.
Machine Learning: Machine learning specifically focuses on enabling computers to learn from data without being explicitly programmed, with the goal of making predictions or decisions based on that data.
3. Approach:
AI: AI can encompass various approaches, including symbolic reasoning, expert systems, and machine learning, among others. It involves both symbolic and statistical techniques to mimic human intelligence.
Machine Learning: Machine learning primarily relies on statistical techniques to enable computers to learn patterns from data and make decisions or predictions without being explicitly programmed.
4. Dependency on Data:
AI: While AI systems may or may not rely on large datasets, they often utilize data to make decisions or improve performance.
Machine Learning: Machine learning heavily depends on data. Algorithms learn from historical data to generalize patterns and make predictions or decisions on new data.
5. Flexibility:
AI: AI systems can be designed to be generalpurpose or specialized for specific tasks. They can incorporate various techniques and may not always require extensive training data.
Machine Learning: Machine learning algorithms are typically more specialized and designed for specific tasks. They require labeled or unlabeled data for training and may not generalize well beyond the specific task they were trained for.
6. Examples:
AI: Examples of AI include virtual assistants (like Siri or Alexa), autonomous vehicles, facial recognition systems, and natural language processing systems.
Machine Learning: Examples of machine learning include recommendation systems (like those used by Netflix or Amazon), spam filters, image recognition systems, and predictive analytics.
Machine learning, on the other hand, specifically focuses on the development of algorithms and models that enable computers to learn from data and improve their performance over time. It is essentially a subset of AI that emphasizes learning from experience rather than relying solely on explicit instructions.
In summary, while artificial intelligence encompasses a diverse array of methodologies aimed at replicating human intelligence, machine learning represents a specific approach within AI that emphasizes learning from data.
Machine learning, a subset of artificial intelligence, encompasses a diverse array of methodologies and techniques aimed at enabling computers to learn from data and improve their performance over time. From making predictions to identifying patterns and optimizing decision-making processes, machine learning plays a crucial role in various domains.
In this comprehensive exploration, we delve into the main types of machine learning, elucidating the fundamental concepts, algorithms, and applications that characterize each category.
Supervised learning involves training a model on a labeled dataset, where each example is associated with a corresponding target or output. The goal is to learn a mapping from input features to the desired output labels, enabling the model to make predictions on unseen data. Common applications of supervised learning include regression, where the target variable is continuous, and classification, where the target variable is categorical. Popular algorithms in supervised learning include linear regression, logistic regression, decision trees, support vector machines (SVM), and neural networks.
Unsupervised learning, on the other hand, deals with unlabeled data, where the objective is to extract meaningful patterns or structures from the input data without explicit guidance. Unlike supervised learning, there are no predefined output labels, and the algorithm must autonomously identify inherent relationships or clusters within the data. Clustering algorithms, such as k-means clustering and hierarchical clustering, are commonly used in unsupervised learning tasks. Dimensionality reduction techniques, such as principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE), are also widely employed to reduce the complexity of high-dimensional data.
Reinforcement learning is a paradigm of machine learning where an agent learns to make sequential decisions by interacting with an environment to maximize cumulative rewards. The agent receives feedback from the environment in the form of rewards or penalties based on its actions, and the objective is to learn a policy that enables the agent to choose actions that lead to the highest long-term reward. Reinforcement learning has been successfully applied to a variety of domains, including robotics, gaming, finance, and autonomous vehicles. Notable algorithms in reinforcement learning include Q-learning, deep Q-networks (DQN), policy gradients, and actor-critic methods.
Supervised learning involves training a model on a dataset where each example is paired with a corresponding label or target variable. The goal is to learn a mapping from input features to the desired output labels, enabling the model to generalize and make accurate predictions on unseen data.
Data Collection and Preparation: Acquiring a diverse and representative dataset containing relevant features and corresponding labels. This dataset is typically split into training, validation, and test sets to facilitate model development and evaluation.
Model Selection and Training: Choosing an appropriate machine learning algorithm based on the nature of the problem and the characteristics of the data. Common algorithms in supervised learning include linear regression, logistic regression, decision trees, support vector machines (SVM), and neural networks. The selected model is then trained on the training data, where it learns patterns and relationships between the input features and the target variable.
Model Evaluation: Assessing the performance of the trained model using evaluation metrics and techniques. This involves evaluating how well the model generalizes to unseen data and its ability to make accurate predictions.
The evaluation of machine learning models is a critical aspect of the model development process, as it provides insights into their performance and guides decision-making regarding model selection and refinement. Several evaluation techniques and metrics are commonly used to assess the performance of supervised learning models:
Accuracy: Accuracy measures the proportion of correctly classified instances out of the total number of instances. While accuracy is a straightforward metric, it may not be suitable for imbalanced datasets where one class is significantly more prevalent than others.
Precision and Recall: Precision measures the proportion of true positive predictions out of all positive predictions, while recall measures the proportion of true positive predictions out of all actual positive instances. These metrics are particularly useful in binary classification tasks, where there is an imbalance between the classes.
F1 Score: The F1 score is the harmonic mean of precision and recall, providing a balance between the two metrics. It is especially useful when there is an uneven class distribution or when both precision and recall are important.
ROC Curve and AUC: Receiver Operating Characteristic (ROC) curves plot the true positive rate (TPR) against the false positive rate (FPR) at various threshold settings. The Area Under the ROC Curve (AUC) provides a single scalar value representing the model's performance across all threshold settings. A higher AUC indicates better overall performance.
Confusion Matrix: A confusion matrix provides a comprehensive summary of the model's predictions compared to the actual labels, showing the counts of true positives, true negatives, false positives, and false negatives.
Domain knowledge refers to expertise and understanding of the specific problem domain or application area. While machine learning algorithms can autonomously learn patterns and relationships from data, domain knowledge plays a crucial role in several aspects of the machine learning process:
Data Interpretation: Understanding the domain context is essential for interpreting the predictions and insights generated by machine learning models. Domain experts can provide valuable insights into the significance and implications of model predictions, helping stakeholders make informed decisions.
Model Selection and Evaluation: Domain knowledge guides the selection of appropriate evaluation metrics and techniques tailored to the specific problem domain. Different domains may prioritize certain performance metrics or have unique considerations that influence the choice of evaluation criteria.
Ethical and Regulatory Considerations: Domain knowledge informs ethical and regulatory considerations associated with the deployment of machine learning models in real-world applications. Domain experts can identify potential biases, fairness issues, and ethical implications that may arise from model predictions, ensuring responsible and ethical AI practices.
Neural networks are a foundational class of machine learning models, drawing inspiration from the structure and operation of the human brain. These networks consist of interconnected nodes, or neurons, organized into layers. The layers typically include an input layer, one or more hidden layers, and an output layer. Each neuron receives input signals, processes them using activation functions, and passes the output to the neurons in the next layer.
During the training process, neural networks adjust the weights of connections between neurons to minimize the error between predicted and actual outputs. Backpropagation, a key algorithm in neural network training, computes the gradients of the loss function with respect to the network's parameters, allowing for iterative updates to the weights through gradient descent optimization.
Through this iterative training process, neural networks learn to capture complex patterns and relationships in the data. They excel at tasks such as image recognition, natural language processing, and predictive analytics, thanks to their ability to extract features and make high-dimensional, non-linear transformations. As a result, neural networks have become foundational tools in modern machine learning and have contributed to significant advancements in various fields, including computer vision, speech recognition, and healthcare.
Deep learning is a subset of machine learning that utilizes deep neural networks, which are composed of multiple layers of interconnected neurons. Deep neural networks are characterized by their ability to automatically learn hierarchical representations of data through the composition of successive layers. Each layer extracts increasingly abstract features from the input data, allowing deep networks to capture complex patterns and relationships.
Deep neural networks have revolutionized various fields, including computer vision, natural language processing, and speech recognition. Convolutional Neural Networks (CNNs) are widely used in computer vision tasks such as image classification and object detection, while Recurrent Neural Networks (RNNs) excel in sequence modeling tasks such as language translation and speech recognition. The development of deep learning algorithms has led to significant breakthroughs in areas such as autonomous vehicles, healthcare diagnostics, and recommendation systems.

Machine learning finds applications across diverse domains, offering solutions to a wide range of problems. Some common applications of machine learning include:
1. Predictive Analytics: Machine learning models are used to forecast future trends and outcomes based on historical data. This includes applications such as sales forecasting, demand prediction, and financial risk assessment.
2. Image and Speech Recognition: Machine learning algorithms enable computers to recognize patterns and objects in images and speech. This technology powers applications such as facial recognition, handwriting recognition, and voice assistants.
3. Healthcare: Machine learning is utilized in medical imaging for disease diagnosis and treatment planning, as well as in personalized medicine for predicting patient outcomes and recommending treatments.
4. Natural Language Processing (NLP): Machine learning techniques are employed to analyze and understand human language, enabling applications such as sentiment analysis, chatbots, and language translation.
5. Fraud Detection: Machine learning algorithms help detect fraudulent activities in various domains, including banking, insurance, and e-commerce, by identifying anomalous patterns in transaction data.
While machine learning offers numerous benefits, it also comes with environmental considerations, particularly in terms of energy consumption and carbon emissions. Training deep neural networks requires significant computational resources, including powerful hardware such as GPUs and TPUs, as well as large-scale data centers for processing and storage.
The energy consumption of training deep learning models can be substantial, contributing to the carbon footprint of machine learning applications. A study by researchers at the University of Massachusetts Amherst estimated that training a single deep learning model could emit as much carbon dioxide as the lifetime emissions of five average American cars.
Efforts to mitigate the environmental impact of machine learning include the development of energy-efficient algorithms, hardware optimization, and the adoption of renewable energy sources for data centers. Additionally, techniques such as model compression and transfer learning can reduce the computational resources required for training and inference, thereby minimizing the environmental footprint of machine learning systems.
A Machine Learning development company India provides comprehensive solutions harnessing ML algorithms for diverse applications. From predictive analytics to image recognition, ML development companies leverage data-driven approaches to extract valuable insights.
With expertise in deep learning and neural networks, these firms offer cutting-edge solutions tailored to specific business needs. ML development company are at the forefront of innovation, driving advancements in AI technology across industries. Their proficiency in ML algorithms and scalable solutions makes them invaluable partners for businesses seeking to capitalize on the power of data-driven decision-making.